
Gravitational Attraction
What would happen if two people out in space a few meters apart, abandoned by their spacecraft, decided to wait until gravity pulled them together? My initial thought was that …
In #religion

I read with interest this article by Than Christopoulos after seeing his debate with Matt Dilahunty which I hope to respond to at some point. Than is very excited about Bayes Theorem and he likes to apply it to religious contexts, both of which are interests of mine, so I got to nerd-out in his article for a while. I like the approach Than uses, and he goes out of his way to insert teaching examples to help the reader along which is nice, but I was disappointed with some of the statements Than made about Paulogia and his motives. Than says about Paulogia "Why offer detailed engagement with a nuanced model when you can say something that sounds smart—especially if you say it with confidence and derision? It’s a pattern I’ve encountered firsthand." One of the points I wish to make in this post is that much of the disagreement which sparked Than's blog post is that the two are talking about different things -- and I hope to show this using Bayesian analysis so that Than will more clearly understand. But to claim that Paulogia is just trying to take cheap shots and can't handle nuance is ridiculous. Just go and watch any of his videos (like Who REALLY wrote the Gospels and How NOT to Defend the Resurrection Against Minimal Witnesses) to see that Paulogia is one of the most careful and considered YouTubers in the field and that it is not a coincidence that the likes of Gary Habbermas, Mike Licona, and even William Lane Craig have had to address his content. So, enough of the ad hominems, let's get to the content.
I have a few goals with this post.
It starts with Paulogia's tweet:

Than replies
"This sounds clever—until you think about it for more than five seconds, because in reality, it reflects a deep misunderstanding of both the methodology and the epistemology behind historical arguments for the resurrection of Jesus."
and later
His one-liner only works if he collapses two distinct things into one. But the Historical Reportage Model (HRM) and the Maximal Data Case are two separate stages of reasoning. They are not interchangeable, and neither functions like the other.
summarized as
So, we separate the historical investigation into two stages:
- What kind of document were the Gospel authors trying to write? (HRM)
- Given that, what actually happened? (Max Data Case)
Than defines his data as,
The Maximal Data Case looks at historically accessible facts—such as (but not limited to):
- The crucifixion of Jesus under Pontius Pilate,
- The early proclamation of the resurrection in Jerusalem,
- The empty tomb (as independently attested across traditions),
- The poly-modal, post-mortem appearances to individuals and groups,
- The conversions of skeptics like James and Paul,
- And the rise of a resurrection-centric movement that exploded across hostile cultural environments…
In other words, given these data points, the question becomes: Which hypothesis best accounts for them? And this is where a formal structure is not just helpful, but necessary.
In formal terms, we are evaluating a likelihood ratio
$$\frac{P(E|H_{\text{Res}}+k)}{P(E|H_{\text{Alt}}+k)} $$Where:
- \(E\) = the body of historical evidence
- \(H_{\text{Res}}\) = the resurrection hypothesis
- \(H_{\text{Alt}}\) = any competing hypothesis (e.g., hallucination theory, theft, legend)
- \(k\) = relevant background knowledge, including the HRM (i.e., that the Gospels are good-faith historical reportage)
Where he notes "HRM is part of the background knowledge (k), not the evidence."
Than continues
Paulogia’s rhetorical move only works if he collapses two distinct stages of reasoning into one—and then flattens them into “because the Bible says so.” But why does this conflation happen so often?
and
If I am being less charitable, it seems to be because if the Historical Reportage Model (HRM) is granted, the resurrection becomes too evidentially powerful to dismiss without shifting the standards. And that’s a problem for the skeptic.
[...]
And here’s the underlying tension: if you’re already committed to the Humean idea that miracle claims are so improbable that no amount of testimony could ever justify belief, then the Maximal Data Case becomes threatening. Because on explanatory grounds alone, the resurrection might actually come out ahead.
finally,
To avoid facing that dilemma, many skeptics opt to short-circuit the conversation entirely.
I really dislike the claim that someone is just performing a "rhetorical move" to "avoid facing" an uncomfortable conclusion -- this seems to invoke mind-reading that I am not confident exists. I've heard it said that it is far too easy to ascribe good reasoning to your side and psychological motives to your opponent, and that is what seems to be happening here. Why would Paulogia state that both HRM and Max Data are equivalent to "for the Bible tells me so"? This is the case even while Than insists that HRM does not imply Biblical inerrancy, taking the stance:
A critic could accept HRM and still say, “Yes, Luke wrote what he believed was accurate—but his sources were wrong.” That’s a fair counter-hypothesis. What’s not fair is pretending that HRM means “Jesus rose because the Gospels say so.” That’s either a category error—or a straw man.
The problem is the following. If you accept the Historical Reportage Model (HRM) (" [the Gospel authors] sought to record the deeds and teachings of Jesus in good faith, based on sources they considered reliable (including eyewitnesses and early oral tradition), and they did not see themselves as having literary license to invent or reshape historical events for purely theological, symbolic, or moral purposes") then you accept things like the authors were eyewitnesses and honestly claimed to have eaten fish and touched the wounds of Jesus after he was crucified and buried for three days. No skeptic accepts this, and the only reason to accept the fish and the wounds story is in fact "for the Bible tells me so" -- the Gospels (and sometimes only one Gospel) is the only source for these stories. The Max Data case, as described in mathematical detail by Than, assumes HRM at every point so it too inherits the "for the Bible tells me so"
All of the math that Than provides doesn't change this fact, but I think we can make it more clear by doing the analysis again, correcting some things along the way, see where Than's analysis fits into the correction and see where that lands us.
Before we embark on the improved solution, we have to state what the problem is. Essentially we are evaluating the claim of the Resurrection, and want to know simply,
where \(R\) represents the model/hypothesis of the Resurrection. In order to accomplish this we need to:
In both of these steps Than drops the ball.
It is annoying that Christian apologists always 1 pull out the least charitable alternative explanations of the Biblical data, and Than is no exception. He comments on hallucination, theft, and legend only. At least he doesn't bother critiquing the swoon theory, which no modern skeptic has ever suggested. What he doesn't do is look at specific alternatives and their explanatory value on the Biblical data, such as James Fodor's RHBS model, Paulogia's Minimal Witnesses model, and Kamil Gregor's Pareidolia model. I find this problematic, because it is easy to argue against the hallucination if you assume that the Biblical texts are mostly reliable and they say that 500 people saw Jesus after 3 days, but this ends up being a strawman. So our problem now becomes,
for all of the models that we want to explore. As a practical matter, when you have more than two models (and even many times with only two models) the full fractional form of the Bayes theorem gets hard to fit easily on the page. The denominator especially can get very long, and obscure the calculation. As such I will use the approach that I describe in my book Statistical Inference for Everyone where I write out the numerators only (and use the ~ symbol instead of =), sum those numerators to a separate term, and then divide by the sum as an extra step. Examples of this can be found here and here. This allows us to seamlessly include as many models as we wish.
Having just said that, also for convenience, I will follow Than's approach and just lump all the alternatives into one, which I'll call \(A\), but keep in mind that to do this properly at the end we need to break that out into some of the specific cases.
The next problem Than has is with the data. He presents things like the "historically accessible facts" above, but that is not the data. The data is we have texts that have stories about..." those "historically accessible facts". For example, the empty tomb is not something that needs to be explained, although the RHBS model does do that. What we have to explain is "we have texts that have stories about...an empty tomb". The Minimal Witnesses model, for example, states that the entire empty tomb narrative -- which stems from one source only -- is easily explained as a fictitious addition to explain certain counter apologetics at the time. The character of Joseph of Arimathea in whose tomb Jesus is supposedly buried has all the hallmarks of a made up character to satisfy certain plot points in the story. Either way, the data could be explained with Than's HRM model but can also be explained with more literary models.
When Than writes down his odds form for the posterior, he writes:
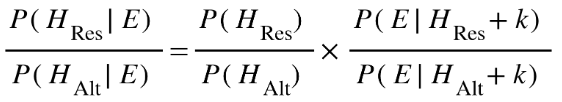
I observe that one would never use the "+" operator to denote extra information. In logic, "+" is attributed to the "or" operation, not the "and" operation which Than wants. One can use "\(\cdot\)", "," or ";" instead. Also, this "background information" denoted by \(k\) should be in all of the terms, not just in the likelihood term. This mistake makes Than think his conclusions are more general than they are. A proper rewriting of this, using Than's notation, is
where \(k\) includes the Historical Reportage Model (HRM). To make this more explicit, and to reduce the number of symbols, and further to avoid some issues with the odds form, I prefer to write this same equation as,
It is my contention that Paulogia (and myself) care about \(P(R|\text{data})\) and we don't care much about \(P(R|\text{data},\text{HRM})\), while Than cares more about the latter than the former -- or at least only addresses the latter not the former. As such, Than interprets Paulogia's dismissal of HRM and the Max Data as "for the Bible tells me so" as a rhetorical move, when in fact they are each talking about different mathematical terms. In order to handle this mathematically we need to relate these two terms, which we can do with a process of marginalization (see page 105 in Loredo's excellent From Laplace to Supernova paper). All this is, is a process of breaking up a single probability term, i.e. \(P(H)\), into a sum of terms conditional on a variable and multiplied by the prior of that variable,
Applying this to the case at hand we have,
I don't see why knowing either \(R\) or \(A\) should effect the probability of HRM, so this simplifies a bit to:
In the article, Than assigns the following prior probabilities
and the following likelihood values given independent evidence/data which he calls \(E_1\) (e.g. crucifixion), \(E_2\) (e.g. Multi-Modal Post-Mortem Appearances), and \(E_3\) (Conversion of Skeptics):
His analysis at all points assumes HRM is true, so he implicitly assigns,
Plugging these into the equations above,
which leads to:
and finally
which agrees with Than.
The big issue is that no skeptic thinks that \(P(\text{HRM})\) is likely, instead it would be \(P(\text{HRM}) \ll P(\neg\text{HRM})\). Where \(\neg\text{HRM}\) includes mixtures, where the texts include some historical elements, some embellishments, some fabrications, etc... What does the calculation look like now?
We start with this,
and admit that even under the \(\neg\text{HRM}\) model, the Resurrection hypothesis fits the data well but so do the alternatives, so we'd have \(P(\text{data}|H,\neg\text{HRM}) \approx P(\text{data}|A,\neg\text{HRM})\) which we will define as "same". Since \(P(\text{HRM}) \ll P(\neg\text{HRM})\), the first term nearly drops out, and the calculation becomes,
So the calculation boils down the priors, and the data has a negligible effect,
Why is that? It's because mundane models can explain the "texts contain stories" data and don't need to explain the "texts contain facts" data.
If one wanted to be more precise here, one would need to look at specific models as I said earlier, and actually handle those alternatives and what the data actually contain.
While I'm here, there are some other random thoughts I had on the article.
: note: I'd love to see an exception ↩
Gravitational Attraction
What would happen if two people out in space a few meters apart, abandoned by their spacecraft, decided to wait until gravity pulled them together? My initial thought was that …
A Simple Physics Problem Gets Messy
A physics problem from a practice AP test came to my attention, when my daughter was in AP physics this past spring. I went over her solutions when she did …

Skepticism and Dubious Medical Procedures
In my discussion with Jonathan McLatchie on the Still Unbelievable podcast, I said that there hasn’t been a verified miracle claim even since Hume’s essay on miracles. Here I look into the papers he references in response.
What problems are you interested in? How can I help?